Building a Collaborative DAW in the Browser
When you think about building a Digital Audio Workstation (DAW), the browser probably isn’t the first platform that comes to mind. But what if you could build a fully featured, collaborative music production tool that runs entirely in the browser with realtime synchronization, multi-track editing, effects chains, and sample-accurate audio playback?
The Challenge: Real-Time Audio Collaboration
Building a DAW is complex enough on its own. Add real-time collaboration, and you’ve got some challenges:
- Timeline synchronization: When one user drags a clip, everyone needs to see it move instantly
- Audio sample management: Large audio files need efficient storage and streaming
- Sample-accurate playback: Audio scheduling needs millisecond precision
- Ownership and permissions: Users should only delete their own clips
- Live mix state: Volume, mute, solo—should these sync across users or stay local?
Let me walk you through how I solved these problems using Convex for realtime data sync and Web Audio API for precise audio scheduling.
Convex: Schema-Driven Real-Time Database
The heart of the collaborative experience is Convex, a real-time backend that automatically syncs data across clients. What makes Convex special is its schema-first approach with automatic TypeScript generation, making it easier to develop and use LLMs to code along with.
Here’s the core schema that powers the timeline:
export default defineSchema({
tracks: defineTable({
roomId: v.string(),
index: v.number(),
volume: v.number(),
muted: v.optional(v.boolean()),
soloed: v.optional(v.boolean()),
})
.index("by_room", ["roomId"])
.index("by_room_index", ["roomId", "index"]),
clips: defineTable({
roomId: v.string(),
trackId: v.id("tracks"),
startSec: v.number(),
duration: v.number(),
leftPadSec: v.optional(v.number()),
bufferOffsetSec: v.optional(v.number()),
name: v.optional(v.string()),
sampleUrl: v.optional(v.string()),
})
.index("by_room", ["roomId"])
.index("by_track", ["trackId"]),
ownerships: defineTable({
roomId: v.string(),
ownerUserId: v.string(),
clipId: v.optional(v.id("clips")),
trackId: v.optional(v.id("tracks")),
})
.index("by_clip", ["clipId"])
.index("by_track", ["trackId"])
.index("by_owner", ["ownerUserId"]),
});Notice the intentional minimalism here. I deliberately avoid storing track names or complex metadata in Convex. Instead, I focus on what needs to be synchronized: positioning, timing, and ownership. Everything else stays client side.
Room-Based Multi-Tenancy
The ownerships table is key to authorization. When a user creates a clip or track, an ownership record is created. This enables enforcing owner-only deletions in Convex mutations:
// Example mutation: only owners can delete their clips
export const deleteClip = mutation({
args: { clipId: v.id("clips") },
handler: async (ctx, { clipId }) => {
const userId = await getUserId(ctx);
const ownership = await ctx.db
.query("ownerships")
.withIndex("by_clip", (q) => q.eq("clipId", clipId))
.first();
if (!ownership || ownership.ownerUserId !== userId) {
throw new Error("Unauthorized: only the owner can delete this clip");
}
await ctx.db.delete(clipId);
await ctx.db.delete(ownership._id);
},
});Effects Chains with Convex
EQ and reverb settings are also stored in Convex, enabling synchronized effect chains across collaborators:
effects: defineTable({
roomId: v.string(),
targetType: v.string(), // 'track' | 'master'
trackId: v.optional(v.id("tracks")),
index: v.number(), // chain order
type: v.string(), // 'eq' | 'reverb'
params: v.any(), // flexible for different effect types
})
.index("by_track", ["trackId"])
.index("by_track_order", ["trackId", "index"])This flexible schema allows different effect types while maintaining ordered chains per track or master bus.
Web Audio API: Sample-Accurate Scheduling
The second pillar is a custom audio engine built on Web Audio API. The challenge with browser DAWs is achieving sample-accurate playback while maintaining the flexibility of a timeline editor.
The Transport System
At the core is a transport system that maps timeline seconds to audio context time:
export class AudioEngine {
private transportEpochCtxTime = 0;
private transportEpochTimelineSec = 0;
private transportRunning = false;
private timelineToCtxTime(timelineSec: number) {
if (!this.audioCtx) return 0;
const delta = timelineSec - this.transportEpochTimelineSec;
return this.transportEpochCtxTime + Math.max(0, delta);
}
onTransportStart(playheadSec: number) {
if (!this.audioCtx) return;
this.transportEpochCtxTime = this.audioCtx.currentTime;
this.transportEpochTimelineSec = Math.max(0, playheadSec);
this.transportRunning = true;
this.scheduleAllClipsFromPlayhead();
}
}When you hit play, the engine captures the current audioContext.currentTime as an epoch and maps all timeline positions relative to it. This enables precise scheduling regardless of when playback starts.
Clip Scheduling with Offsets
Each clip can have trimming and padding, so scheduling needs to account for buffer offsets:
scheduleClip(
clip: Clip,
buffer: AudioBuffer,
playheadSec: number
) {
if (!this.audioCtx) return;
const startSec = clip.startSec + (clip.leftPadSec || 0);
if (playheadSec > startSec + clip.duration) return; // already past
const bufferOffset = clip.bufferOffsetSec || 0;
const playOffset = Math.max(0, playheadSec - startSec);
const bufferStart = bufferOffset + playOffset;
const remainingDuration = clip.duration - playOffset;
const scheduleTime = this.timelineToCtxTime(
Math.max(startSec, playheadSec)
);
const source = this.audioCtx.createBufferSource();
source.buffer = buffer;
source.connect(this.getTrackChain(clip.trackId));
source.start(scheduleTime, bufferStart, remainingDuration);
this.activeSources.push(source);
}This handles:
- Left padding: Silent space before audio starts in the clip window
- Buffer offset: Trimming from the left (start playing X seconds into the sample)
- Playhead offset: Resume playback mid-clip if user seeks
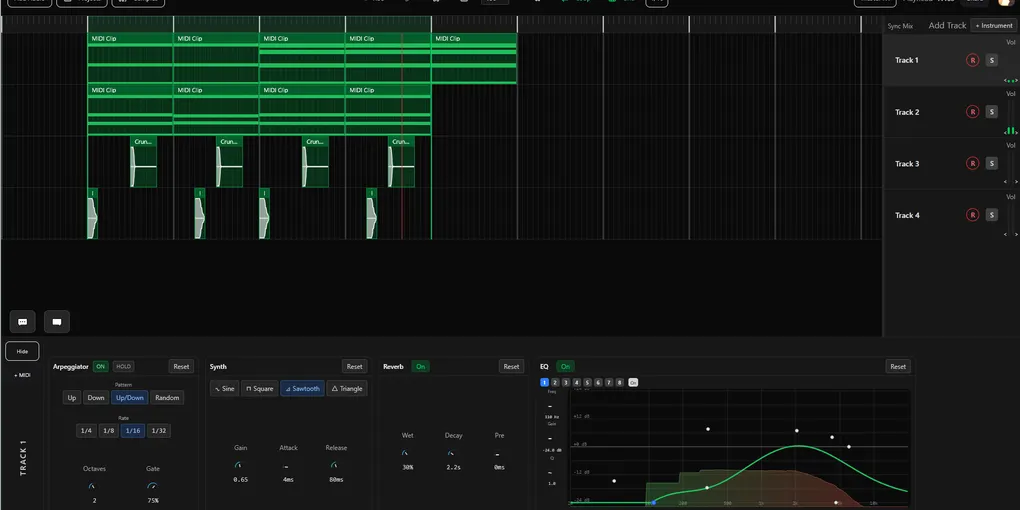
Effect Chains: Per-Track EQ and Reverb
Each track has its own effects chain built with Web Audio nodes:
private rebuildTrackRouting(trackId: string) {
const input = this.trackInputs.get(trackId);
const gain = this.trackGains.get(trackId);
if (!input || !gain) return;
// Disconnect current routing
try { input.disconnect(); } catch {}
const eqChain = this.eqChains.get(trackId) || [];
// Build the chain: input -> [EQ nodes] -> gain -> master
let currentNode: AudioNode = input;
for (const eqNode of eqChain) {
currentNode.connect(eqNode);
currentNode = eqNode;
}
const reverb = this.trackReverbs.get(trackId);
if (reverb?.enabled) {
// Parallel wet/dry routing
currentNode.connect(reverb.dryGain);
currentNode.connect(reverb.preDelay);
reverb.preDelay.connect(reverb.convolver);
reverb.convolver.connect(reverb.wetGain);
reverb.dryGain.connect(gain);
reverb.wetGain.connect(gain);
} else {
currentNode.connect(gain);
}
gain.connect(this.masterGain);
}This routing system:
- Connects EQ nodes in series (each BiquadFilter applies frequency shaping)
- Implements parallel dry/wet routing for reverb
- Maintains clean separation between track input, effects, and output gain
Metronome with Lookahead Scheduling
The metronome demonstrates precise timing with a lookahead scheduler:
private scheduleMetronomeTicks() {
if (!this.transportRunning || !this.metronomeEnabled) return;
const nowCtx = this.audioCtx.currentTime;
const scheduleUntil = nowCtx + this.metronomeLookaheadSec; // 250ms ahead
const secondsPerBeat = 60 / this.bpm;
let nextBeatTimeline = this.nextMetronomeBeatTimelineSec;
while (nextBeatTimeline) {
const eventTime = this.timelineToCtxTime(nextBeatTimeline);
if (eventTime > scheduleUntil) break;
if (eventTime >= nowCtx - 0.02) { // small tolerance
const source = this.audioCtx.createBufferSource();
source.buffer = this.metronomeBuffer;
source.connect(this.metronomeGain);
source.start(eventTime);
this.metronomeSources.push(source);
}
nextBeatTimeline += secondsPerBeat;
}
this.nextMetronomeBeatTimelineSec = nextBeatTimeline;
}This runs every 50ms, scheduling clicks 250ms in advance. The Web Audio API’s precise scheduling ensures sample-accurate timing even if JavaScript execution is delayed.
MediaBunny: Browser-Native Audio Recording
One of the most interesting features of the DAW is the ability to record audio directly from your microphone and add it to the timeline. For this, I use MediaBunny—a pure TypeScript media toolkit that handles audio recording, encoding, and metadata extraction entirely in the browser.
MediaBunny is perfect for browser-based DAWs because it’s:
- Dependency-free: No need for server-side processing or FFmpeg binaries
- Format-agnostic: Works with WebM, MP4, WAV, and more
- TypeScript-native: Excellent type safety and IDE support
- Lightweight: Only ~5KB when tree-shaken
Recording Pipeline with MediaBunny
Here’s how the recording workflow integrates MediaBunny with the browser’s MediaStream API:
import {
Output,
BufferTarget,
WebMOutputFormat,
MediaStreamAudioTrackSource,
QUALITY_MEDIUM,
} from 'mediabunny';
const startRecording = async () => {
// Request microphone access
const mediaStream = await navigator.mediaDevices.getUserMedia({
audio: {
echoCancellation: true,
noiseSuppression: true,
sampleRate: 44100,
},
});
const audioTrack = mediaStream.getAudioTracks()[0];
// Create MediaBunny output with WebM container
const output = new Output({
format: new WebMOutputFormat(),
target: new BufferTarget(), // Record to in-memory buffer
});
// Create audio source from the live MediaStream track
const audioSource = new MediaStreamAudioTrackSource(audioTrack, {
codec: 'opus',
bitrate: QUALITY_MEDIUM,
});
output.addAudioTrack(audioSource);
await output.start(); // Begin recording
};This creates a live audio pipeline that continuously encodes microphone input to Opus-compressed WebM. The BufferTarget accumulates the encoded data in memory, ready for export when recording stops.
Stopping and Analyzing Recordings
When the user stops recording, MediaBunny finalizes the output and provides the encoded buffer:
const stopRecording = async () => {
// Stop all media tracks
mediaStream.getTracks().forEach(track => track.stop());
// Finalize MediaBunny output
await output.finalize();
const buffer = (output.target as BufferTarget).buffer;
// Create a blob from the encoded data
const blob = new Blob([buffer], { type: 'audio/webm' });
// Analyze the recording to extract metadata
const audioFile = await analyzeAudioFile(blob, `recording-${Date.now()}.webm`);
};Metadata Extraction
MediaBunny’s Input class can parse audio files and extract detailed metadata—crucial for properly scheduling clips on the timeline:
import { Input, ALL_FORMATS, BlobSource } from 'mediabunny';
const analyzeAudioFile = async (blob: Blob, fileName: string) => {
const input = new Input({
formats: ALL_FORMATS,
source: new BlobSource(blob as File),
});
// Extract duration and track metadata
const duration = await input.computeDuration();
const audioTrack = await input.getPrimaryAudioTrack();
if (!audioTrack) {
throw new Error('No audio track found');
}
return {
name: fileName,
blob,
duration,
sampleRate: audioTrack.sampleRate,
numberOfChannels: audioTrack.numberOfChannels,
url: URL.createObjectURL(blob),
};
};This metadata extraction is essential because:
- Duration: Determines the clip’s length on the timeline
- Sample rate: Ensures proper playback speed through Web Audio API
- Channel count: Enables stereo/mono routing decisions
From Recording to Timeline
Once MediaBunny has captured and analyzed the audio, the workflow is:
- Upload to R2: The audio blob is sent to the Cloudflare Worker for storage
- Create Convex clip: A new clip document is created with the R2 URL
- Schedule playback: The audio engine decodes the buffer and schedules it for playback
This seamless integration between MediaBunny, Convex, and the audio engine enables a professional recording workflow entirely in the browser—no server-side processing required.
Edge Infrastructure: Cloudflare Workers + R2
Audio files are large, so efficient storage and streaming is critical. I use Cloudflare R2 for object storage, accessed through a Hono Worker API:
// Upload endpoint
app.post('/api/samples', async (c) => {
const { user } = c.var;
if (!user) return c.json({ error: 'Unauthorized' }, 401);
const formData = await c.req.formData();
const file = formData.get('file') as File;
const roomId = formData.get('roomId') as string;
const key = `rooms/${roomId}/clips/${file.name}`;
await c.env.AUDIO_SAMPLES.put(key, file.stream(), {
httpMetadata: { contentType: file.type },
});
const url = `/api/samples/${roomId}/${encodeURIComponent(file.name)}`;
return c.json({ url, key });
});The streaming endpoint serves audio with proper caching headers:
app.get('/api/samples/:roomId/:filename', async (c) => {
const { roomId, filename } = c.req.param();
const key = `rooms/${roomId}/clips/${filename}`;
const object = await c.env.AUDIO_SAMPLES.get(key);
if (!object) return c.notFound();
return new Response(object.body, {
headers: {
'Content-Type': object.httpMetadata?.contentType || 'audio/wav',
'Cache-Control': 'public, max-age=31536000',
'X-R2-Key': key,
},
});
});This edge-first approach means audio samples are served from Cloudflare’s global network with minimal latency.
Lessons Learned
Building this DAW taught me several valuable lessons:
1. Embrace eventual consistency: Users must have local-only preferences (solo/mute) while other edits sync globally. Not everything needs real-time sync.
2. Schema minimalism: Convex works best with minimal, focused schemas. Store only what truly needs synchronization.
3. Lookahead scheduling is essential: Web Audio scheduling is sample-accurate, but JavaScript isn’t. Always schedule audio events ahead of time.
4. TypeScript everywhere pays off: From Convex schema to audio engine types, type safety caught countless bugs during development.
5. Edge infrastructure matters: Serving audio from R2 through Cloudflare’s network.
What’s Next?
The project is live and functional, but there’s always more to explore:
- MIDI support for virtual instruments
- Audio effects like compression and delay
- Collaborative mixing with per-user mix snapshots
- Offline editing with sync when reconnected
If you’re interested in real-time collaboration, audio programming, or edge computing, I encourage you to check out the live demo and explore the source code.
Building a DAW in the browser pushes the limits of what’s possible on the web platform—and it’s incredibly rewarding to see it all come together.